Yesterday, I tried logging in to my Raspberry Pi server from my phone using ConnectBot, an Android SSH client. It was disconnected immediately. Something is wrong. When being back at home, I tried logging in from my desktop, with the same problem. Pre-authentication disconnect.
It appears, when being booted headless, the Raspberry Pi enables a console at its composite port. Being located behind my tv, it’s easy to plug in a cable. systemctl status sshd indicated an error state, and it refused to start again. It would immediately get killed by a sigbus. A sigbus??? wtf?
The logfiles show the following error:
Mar 9 17:55:19 rpi-server sshd[21742]: Inconsistency detected by ld.so: dl-version.c: 224: _dl_check_map_versions: Assertion `needed != ((void *)0)' failed!
I assumed some upgrade I ran earlier upgraded some libraries, conflicting with some in-momory code, therefore I decided to reboot the Pi.
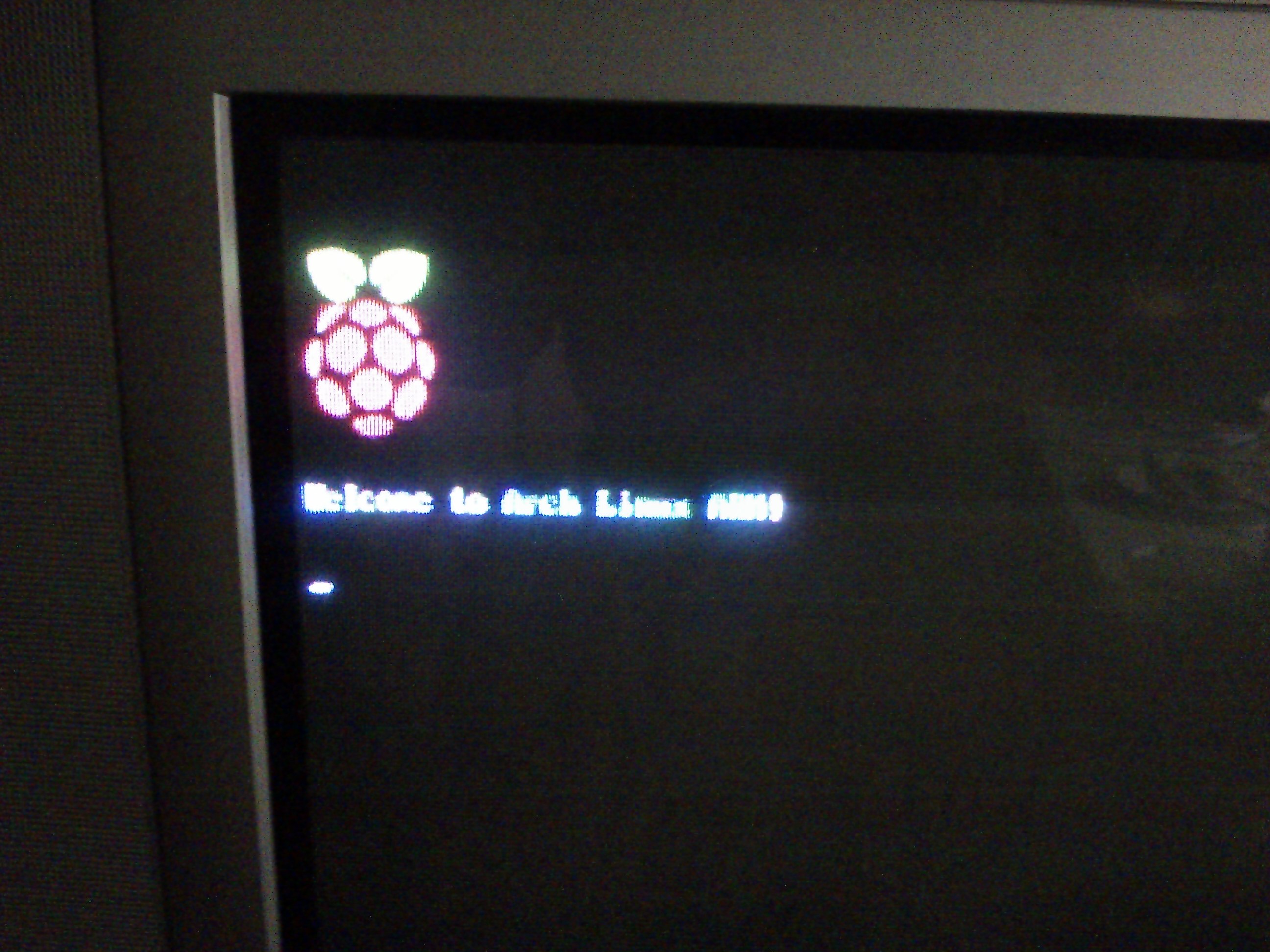
It comes up with the Raspberry logo, saying welcome to ArchLinux ARM, but then it just hangs. Nothing else happens. Nothing.
To verify if it’s the Pi, I decided to boot it up using the SD card from my other Pi. Since it boots fine, there is something wrong with the content of the rpi-server’s SD card, which seems to be confirmed by
Mar 9 17:55:14 rpi-server kernel: [3514985.125660] EXT4-fs error (device mmcblk0p2): __ext4_ext_check_block:475: inode #699: comm systemctl: bad header/extent: inval
id extent entries - magic f30a, entries 223, max 340(340), depth 0(0)
I have made an image if the SD card’s current state. I can restore the SD card with an earlier image I’ve made when installing rpi-server. I think I have changed some things since I’ve made that image, but the basic functionality, such as NFS, CUPS and SANE should be on there. (As I’ve mentioned I was going to make this backup in a post mentioning sane.
So, this seems to be a case of file system corruption. The question remains what caused this corrupt file system? Is there something wrong with the Pi? the SD card? Is there a bug in the kernel used by ArchLinuxARM? Was the system possibly hacked?
I ran fsck -y /dev/mmcblk0p2 on the SD card. I have a backup anyways, so the -y won’t hurt. I have mentioned, even though I marked it as “should be checked on boot” in my fstab, it doesn’t appear to be doing so for the rootfs. (It checks the bootfs during boot) But since this system is supposed to be always up, a check during boot shouldn’t make much difference. And in principe, the file system should not get corrupted. So…. why did it become corrupted?
Anyhow, getting multiple claimed blocks. Therefore I say it’s no use to continue, I should just write the old image back and that be it…. thinking about what I’ve installed afterwards… one of the things would be apache I guess…
My laptop’s SD slot stopped working due overheating. The samn /etc/cpufreq-bench.conf was set to governor ondemand. I have set it to powersave a dozen times, but it keeps popping back to ondemand, probably during the installation of updates. I don’t know why, but I need to clock down my laptop to the lowest possible speed or else it will overheat. The SD slot is the first thing to give issues when this happens.
Running on the image I put back, and performed an upgrade, I see these messages in my logs again:
[ 1417.529973] EXT4-fs error (device mmcblk0p2): ext4_ext_check_inode:462: inode #55228: comm pacman: bad header/extent: invalid magic - magic f34a, entries 1, max 4(0), depth 0(0)
I did the upgrade immediately and rebooted, so it is still either the SD card or the current kernel.